RLSD: Обучение на специализирани AI агенти с минимални ресурси
Обучението на AI модели, способни на сложно логическо разсъждение, традиционно изисква изчислителни ресурси, с каквито разполагат само най-големите технологични гиганти. Инженерните екипи често са принудени да избират между „дистилация“ на знание от огромни и скъпи модели или разчитане на методи за подсилено обучение (reinforcement learning), които обаче страдат от оскъдна обратна връзка.
Според публикация на VentureBeat [1], изследователи от JD.com и няколко академични институции са представили нова парадигма за обучение, наречена RLSD (Reinforcement Learning with Verifiable Rewards with Self-Distillation). Техниката съчетава надеждното проследяване на производителността от подсиленото обучение с детайлната обратна връзка на самодистилацията (self-distillation).
Изображение: Chenxu Yang et al. / arXiv / CC BY 4.0
Проблемът с традиционните методи
Стандартният метод за обучение на разсъждаващи модели е RLVR (Reinforcement Learning with Verifiable Rewards). При него моделът се учи чрез проба и грешка, насочван от крайния резултат. Автоматизиран верификатор проверява дали отговорът е правилен или грешен, предоставяйки бинарна награда (0 или 1).
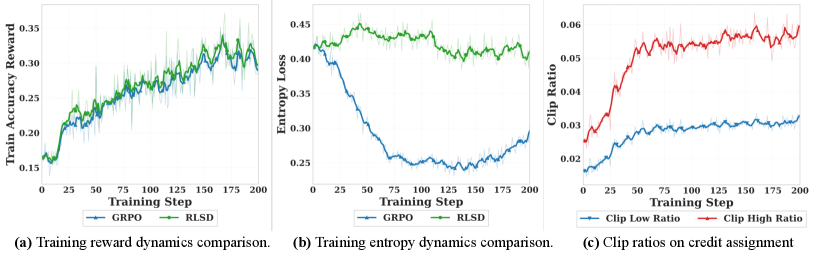
RLVR обаче страда от т.нар. „оскъдна обратна връзка“. Ченсу Янг, съавтор на разработката [2], обяснява, че дълга верига от разсъждения получава само една награда накрая. Моделът не разбира кои точно междинни стъпки са довели до успеха или провала.
Алтернативата, известна като On-Policy Distillation (OPD), изисква по-малък „студентски“ модел да се учи от по-голям „учителски“ модел токен по токен. Това осигурява детайлна обратна връзка, но изисква огромен изчислителен ресурс за поддържане на двата модела едновременно и налага ограничения върху архитектурата им.
Решението: RLSD
RLSD надгражда над тези методи, как разделя сигнала за посоката на обновяване на параметрите от сигнала за неговия мащаб.
- Посока: Верифицируемата обратна връзка от околната среда (RLVR) определя дали моделът изобщо трябва да се учи в дадена посока (т.е. дали отговорът е верен).
- Мащаб: Самодистилацията (където моделът е едновременно учител и студент) определя колко голяма тежест или наказание да получи всяка отделна стъпка от разсъждението.
Този подход елиминира нуждата от външен „учителски“ модел и избягва проблема с „изтичането на информация“, типичен за досегашните опити за самодистилация (OPSD), където моделът започва да халюцинира препратки към невидими за него решения.
Изображение: Chenxu Yang et al. / arXiv / CC BY 4.0
Резултати и приложение
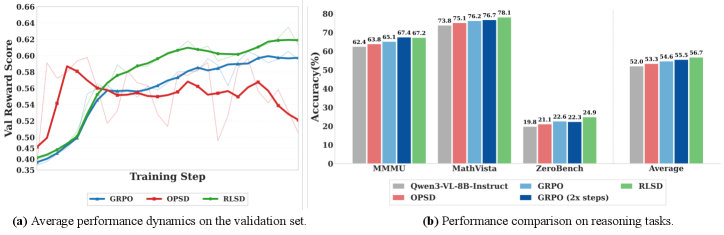
В тестове с мултимодалния модел Qwen3-VL-8B, RLSD значително превъзхожда класическите алгоритми. Методът постига средна точност от 56,18% в пет сложни бенчмарка (включително MathVision и ZeroBench), изпреварвайки стандартното подсилено обучение с над 2%. Освен това, RLSD показва двойно по-бърза конвергенция – постига същите резултати за 200 стъпки на обучение, за които на стандартните методи са нужни 400.
За корпоративни цели RLSD е особено обещаващ, тъй като позволява на екипите да използват собствени данни (наръчници, документация, сорс код) като „привилегирована информация“ за обучение на малки, но високоспециализирани AI агенти, без да се налага изпращане на данни извън вътрешната мрежа.
Източници:
[1]: How to build custom reasoning agents with a fraction of the compute - VentureBeat
[2]: Self-Distilled RLVR - arXiv