Google Gemma 4 ускорява работата си до 3 пъти чрез спекулативно декодиране
Google представи значително подобрение за своята фамилия отворени модели Gemma 4, пускайки специализирани „чертожници“ (drafters) за технологията Multi-Token Prediction (MTP). Според публикация на Ars Technica [1], тази иновация позволява на моделите да предвиждат бъдещи токени и да ускорят процеса на генериране до 3 пъти върху широк спектър от потребителски хардуер.
Основните предизвикателства пред работата на локален ИИ обикновено са свързани с ограничената скорост на паметта (bandwidth), а не с липсата на изчислителни цикли. Когато един модел генерира текст авторегресивно – токен по токен – той често губи време в пренос на данни между паметта и изчислителните ядра. MTP адресира точно този проблем чрез използването на спекулативно декодиране.

Изображение: Svetni.me / Авторско изображение
Изображение: Google чрез Ars Technica
Механизъм на работа и ефективност
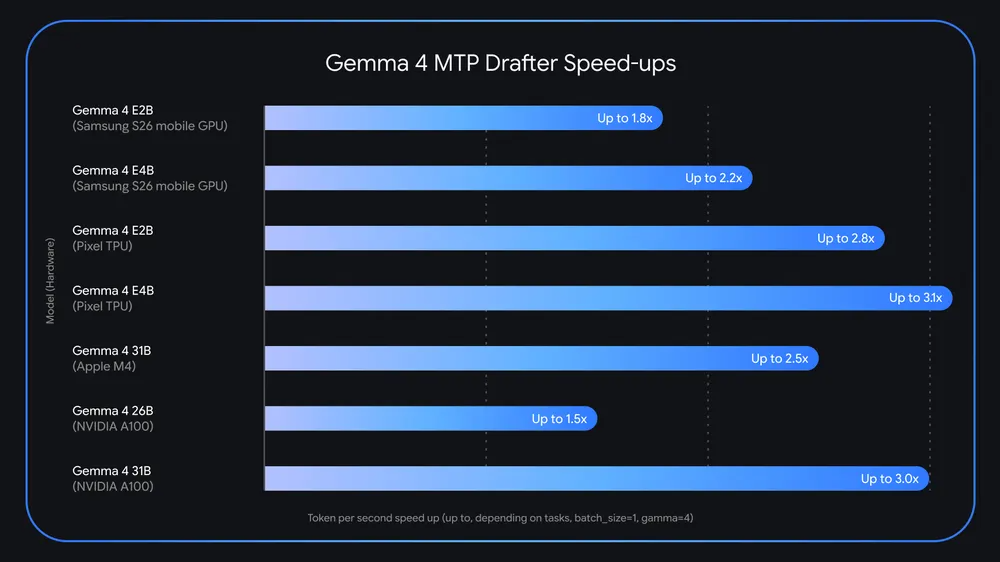
Системата използва изключително леки модели „чертожници“ (например моделът E2B е само със 74 милиона параметъра), които работят паралелно с основния модел Gemma 4. Тези малки модели правят бързи предположения за следващите няколко токена. Основният модел проверява тези предположения наведнъж, като по този начин може да приеме цяла поредица в рамките на едно изчисление.
Тъй като големият модел винаги верифицира изхода, Google гарантира, че технологията не води до никакво влошаване на качеството на отговорите. В тестовете на компанията:
- Смартфони Pixel постигат между 2.8x и 3.1x по-висока скорост.
- Устройства с чип Apple M4 ускоряват работата на 31B модела с 2.5x.
- Потребителските видеокарти (GPU) също се възползват от подобрената ефективност.
Достъпност и интеграция
Заедно с новата технология, Google затвърждава ангажимента си към отворените стандарти, предлагайки Gemma 4 под лиценза Apache 2.0. Новите MTP оптимизации вече са достъпни в популярни рамки за локална работа с ИИ, включително MLX, VLLM, SGLang и Ollama.
Това развитие прави Gemma 4 един от най-конкурентните модели за работа на „крайни“ (edge) устройства, като позволява на потребителите да се възползват от мощни възможности за ревю на код и текстова обработка с минимално забавяне и подобрен живот на батерията за мобилни устройства.
Източници:
[1]: Google’s Gemma 4 AI models get 3x speed boost by predicting future tokens - Ars Technica