По-добри експерименти с LLM Evals: фуния, а не разклонение
Според публикация в инженерния блог на Spotify [1], компанията внедрява нова методология за подобряване на продуктовите експерименти чрез използването на LLM Evals. Вместо да избират между скоростта на автоматизираните оценки и точността на реалните тестове, инженерите предлагат модел на „фуния“, в който двете технологии работят в синхрон.

Авторско изображение / Spotify Engineering
Разликата между верификация и валидация
Основният аргумент в анализа е разграничаването на две ключови фази. LLM Evals (автоматизирани AI „съдии“) служат за верификация — те проверяват дали изходният резултат съответства на зададените стандарти за качество (уместност, тон, кохерентност) още преди функцията да достигне до крайните потребители.
От друга страна, A/B тестването служи за валидация. То измерва как реалните хора реагират на промяната и дали тя води до желаните бизнес резултати, като същевременно следи за непредвидени странични ефекти (например сривове или влошаване на вторични метрики).
Еволюцията на фунията
В предложената от Spotify „експериментална фуния“, автоматизираните оценки действат като филтър. Те позволяват на екипите бързо да отхвърлят неуспешни идеи и да прецизират хипотезите си. Така до фазата на реално тестване достигат само най-обещаващите варианти, което значително повишава процента на успешни експерименти.
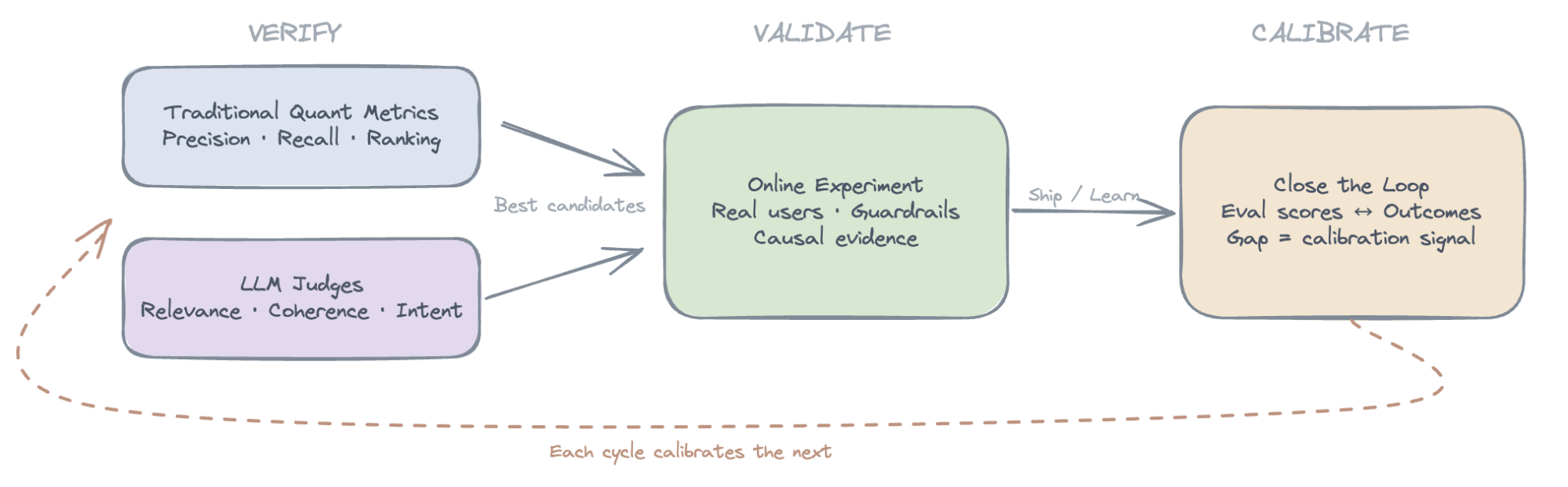
Авторско изображение / Spotify Engineering
Едно от най-големите предимства на този подход е възможността за откриване на модели, които екипите дори не са подозирали. Например, AI съдия може да забележи специфични типове неуместни препоръки, които по-късно да станат основа за нови продуктови подобрения.
Затваряне на цикъла чрез калибриране
Ключовият елемент за дългосрочен успех е калибрирането на сигналите. Инженерите на Spotify съпоставят предпочитанията на AI съдията с реалното поведение на потребителите от A/B тестовете.
Ако AI моделът е предпочел вариант А, но потребителите са реагирали по-добре на вариант Б, това е критичен сигнал за прекалибриране на автоматизираната система. Чрез този обратен цикъл и двата инструмента — оценките и експериментите — стават по-прецизни с времето.
Източници:
[1]: Better Experiments with LLM Evals — A funnel, not a fork - Spotify Engineering